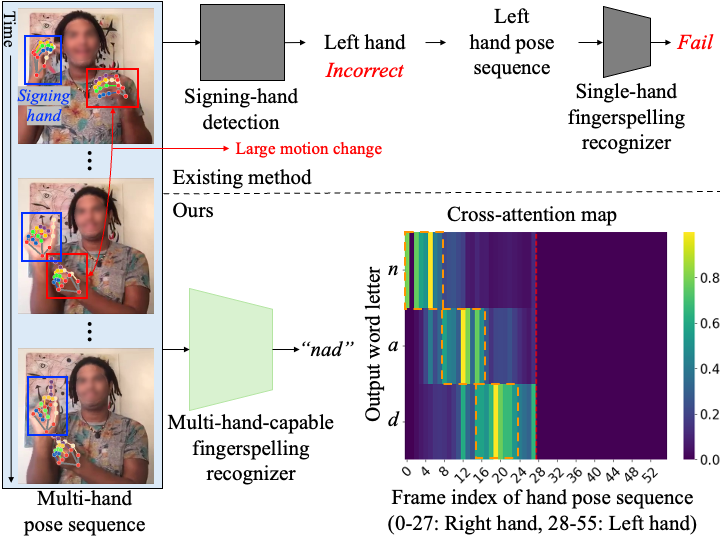
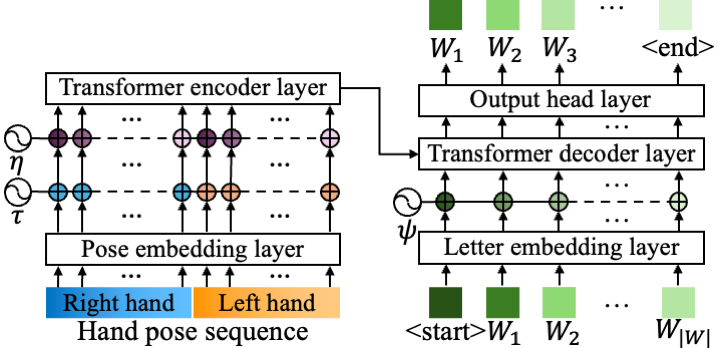
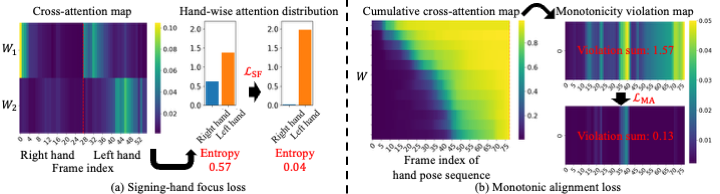
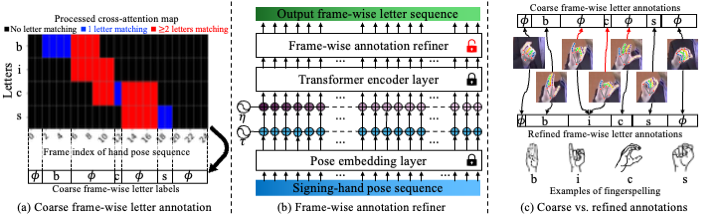
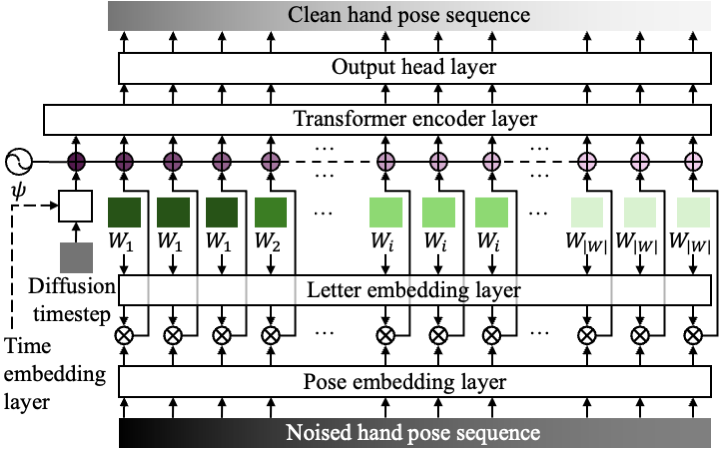
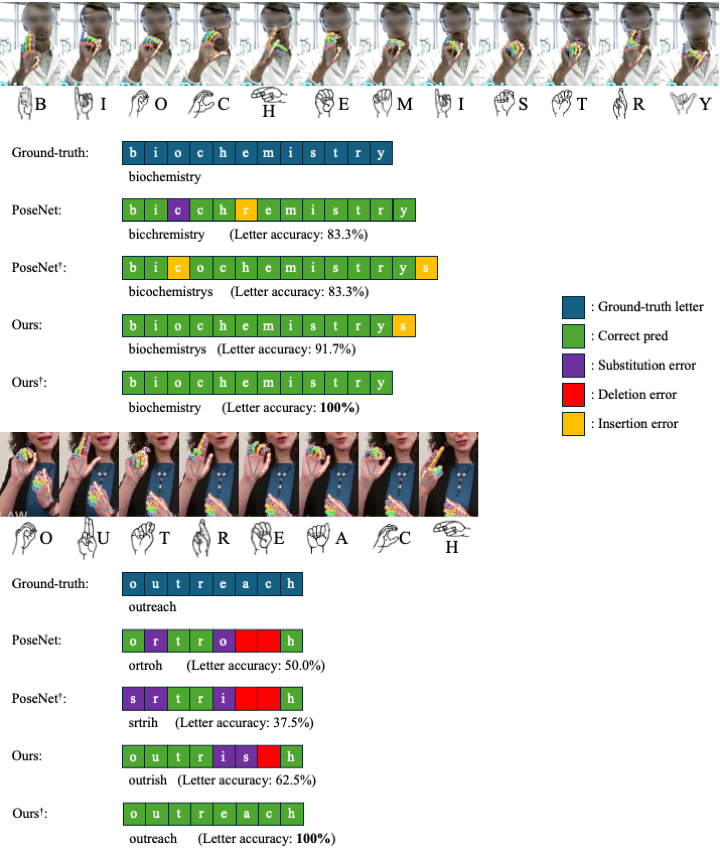
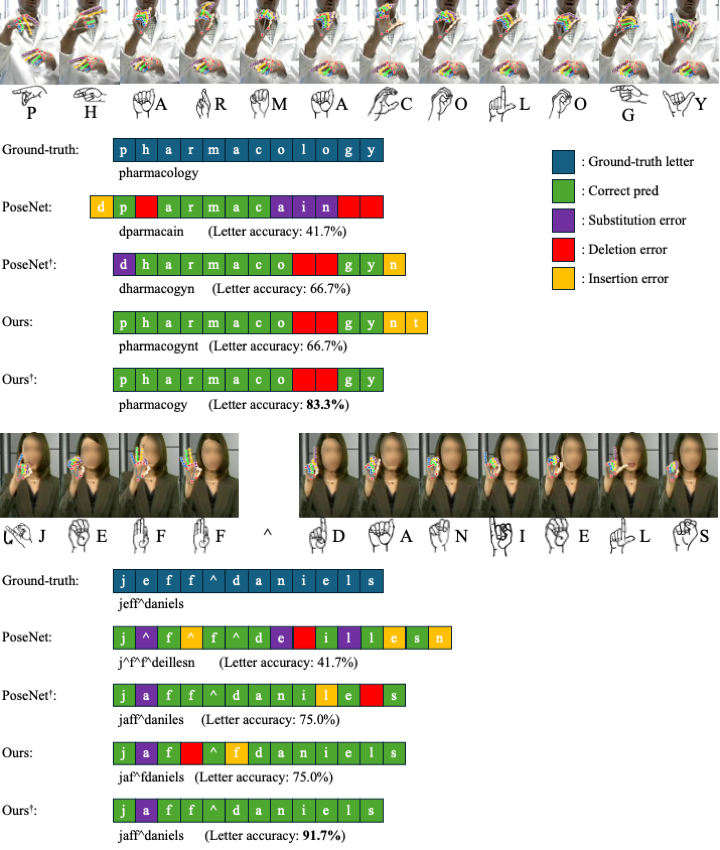
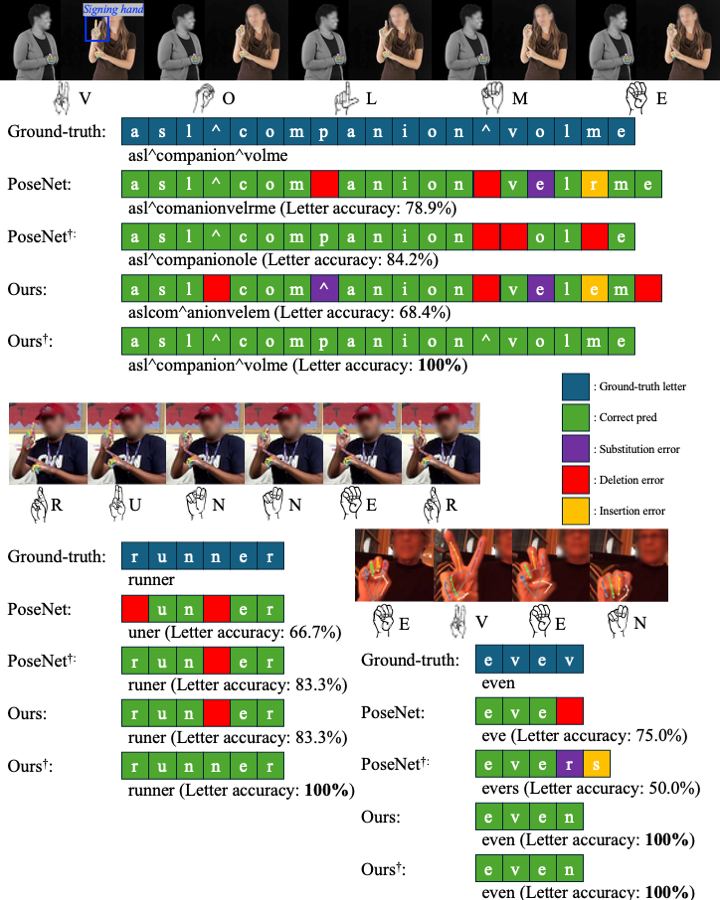
Fingerspelling is a component of sign languages in which words are spelled out letter by letter using specific hand poses. Automatic fingerspelling recognition plays a crucial role in bridging the communication gap between Deaf and hearing communities, yet it remains challenging due to the signing-hand ambiguity issue, the lack of appropriate training losses, and the out-of-vocabulary (OOV) problem. Prior fingerspelling recognition methods rely on explicit signing-hand detection, which often leads to recognition failures, and on a connectionist temporal classification (CTC) loss, which exhibits the peaky behavior problem. To address these issues, we develop OpenFS, an open-source approach for fingerspelling recognition and synthesis. We propose a multi-hand-capable fingerspelling recognizer that supports both single- and multi-hand inputs and performs implicit signing-hand detection by incorporating a dual-level positional encoding and a signing-hand focus (SF) loss. The SF loss encourages cross-attention to focus on the signing hand, enabling implicit signing-hand detection during recognition. Furthermore, without relying on the CTC loss, we introduce a monotonic alignment (MA) loss that enforces the output letter sequence to follow the temporal order of the input pose sequence through cross-attention regularization. In addition, we propose a frame-wise letter-conditioned generator that synthesizes realistic fingerspelling pose sequences for OOV words. This generator enables the construction of a new synthetic benchmark, called FSNeo. Through comprehensive experiments, we demonstrate that our approach achieves state-of-the-art performance in recognition and validate the effectiveness of the proposed recognizer and generator. We release the code and processed data.