DINOv2 PCA visualization code
DINOv2
Foundation models such as CLIP and DINO have garnered significant attention from researchers. To keep up with recent technological advances, I have studied DINOv2. Briefly, DINOv2 excels in extracting semantic features due to its training with a Self-Supervised Learning (SSL) method. This ability is evident in Figure 1 of the DINOv2 paper, which visualizes the first three components of PCA. In this figure, similar parts of objects are colored the same. For instance, the wings of an eagle and an airplane are green, while their heads are red. These results demonstrate DINOv2’s proficiency in extracting semantic features from images. I have implemented code to reproduce this PCA visualization.
PCA visualization
For my analysis, I used four images of different dog breeds (a Corgi, a Shiba Inu, and a Retriever), each in various poses and shapes.
 |
 |
 |
 |
However, the PCA values (RGB) indicated similar parts of the dogs. For example, feet are colored purple and heads are colored orange.
Result

These results confirm DINOv2’s capability to extract useful and semantic features from an image.
Code
For a more detailed view of the implementation, please visit my GitHub repository
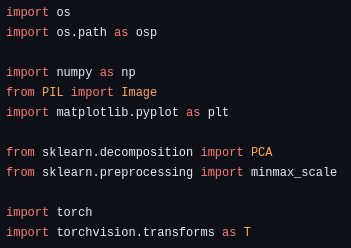 Firstly, various libraries such as ‘sklearn’ for PCA and ‘torch’ for DINOv2 are loaded.
Firstly, various libraries such as ‘sklearn’ for PCA and ‘torch’ for DINOv2 are loaded.
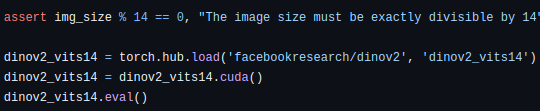 The input image size should be exactly divisible by 14.
The input image size should be exactly divisible by 14.
DINOv2 can be loaded with torch.hub.
You can choose the DINOv2 version like ‘dinov2_vits14’.
import torch
# DINOv2
dinov2_vits14 = torch.hub.load('facebookresearch/dinov2', 'dinov2_vits14')
dinov2_vitb14 = torch.hub.load('facebookresearch/dinov2', 'dinov2_vitb14')
dinov2_vitl14 = torch.hub.load('facebookresearch/dinov2', 'dinov2_vitl14')
dinov2_vitg14 = torch.hub.load('facebookresearch/dinov2', 'dinov2_vitg14')
# DINOv2 with registers
dinov2_vits14_reg = torch.hub.load('facebookresearch/dinov2', 'dinov2_vits14_reg')
dinov2_vitb14_reg = torch.hub.load('facebookresearch/dinov2', 'dinov2_vitb14_reg')
dinov2_vitl14_reg = torch.hub.load('facebookresearch/dinov2', 'dinov2_vitl14_reg')
dinov2_vitg14_reg = torch.hub.load('facebookresearch/dinov2', 'dinov2_vitg14_reg')
 This PCA model is utilized for background removal.
This PCA model is utilized for background removal.
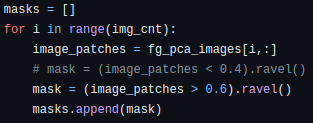 Masks for each image are created using the PCA model. The value 0.6 is determined empirically
Masks for each image are created using the PCA model. The value 0.6 is determined empirically
 This PCA model is used for visualizing semantic features. The PCA model inputs foreground pixels
This PCA model is used for visualizing semantic features. The PCA model inputs foreground pixels x_norm_patchtokens[i,masks[i],:].
 This PCA model is also used for feature visualization. However, unlike the previous model, this one processes all pixels, including the background,
This PCA model is also used for feature visualization. However, unlike the previous model, this one processes all pixels, including the background, x_norm_patchtokens.
The results can be shown below.

For more detailed code, please click on this link. If you have any questions, feel free to contact me via email at jucha@unist.ac.kr.